Disclaimer. All the opinions and recommendations are my own. Do not believe in words only – test and adjust to your case. Think before applying to production environment ?
Everything depends on the use-case.
–Captain Obvious
Hi there
Today I would like to talk to you about several non-trivial but effective approaches (or design patterns) for architecting solutions with Cosmos DB. These methods are structural in nature meaning they are using other services and tools to optimize Cosmos DB workloads.
Generally, I am not a big fan of pre-mature optimizations. Also, after couple of disastrous attempts to see patters everywhere (try to guess whose book I was reading at that time) I am very cautious about patterns.
However, I was collecting these techniques over the last 8 years in NoSQL projects with tons of different technologies including Azure Cosmos DB, Mongo DB, Cassandra, and some others. I find these patterns useful mainly for those who have already achieved results close to optimal with all the existing Cosmos DB optimizations and good practices.
But for those who are only planning to build something on Cosmos DB it makes sense to keep these approaches in mind while designing and building applications so you can use them later on.
Once again, before we begin, I would like to stress out that all the Microsoft recommendations are still valid and allow achieving good results.
Among approaches discussed in this long read I would like to name a few:
- Profiling for Purpose.
- Caching.
- Streaming.
- Data Offloading.
- Dealing with Large-Scale Events using temporary structures.
- Data Migration Scripts as a Core Design Block.
- Designing a Test/Dev environment.
- Data Migration Engine.
In conclusion we will briefly discuss an answer to “Why to use Cosmos DB?” question.
Before we begin
Before we jump to “advanced” optimization cases and strategies, I would like to recap some of the best practices provided by Microsoft.
- Some very good practices to follow while designing Cosmos DB workloads are summarized in a video here.
- Some additional recommendations (that should be applied on collection and application levels):
- Some more features of Cosmos DB which can be used to further optimize your costs:
So, if you have looked through these materials and are pretty sure that your case is much more complex, let’s get started.
Profiling for Purpose
Quite often our workloads are serving certain purpose. Well, ideally, they do … Anyway.
The mechanism on the picture is a self-moving chainsaw (credits to my son Rodion, not yet on LinkedIn)
Point is that we can use this purpose for organizing stable, predictable, and efficient data lifecycle.
Profiling for Purpose
For instance, we have a game or any other B2C application. We are serving different customers which typically are organized into groups. These can be freemium customers, standard customers, premium customers etc.
Obviously, these customers will have similar data model but very different amount of data, ways to process this data (different services) and different SLAs. What does it look like in case of one single collection?
All our customers are stored in one collection. Let’s assume that our goal is to decrease the latency for our premium customers worldwide. What do we do? We are using Multi-Master. Wait a second, since this is only one collection (okay, one set of collections), we have to pay for all our users regardless if they are premium or freemium, right? Ok, the good side is that we have our latency reduced for all customers worldwide, fingers crossed that free-tier customers will notice that and will buy a premium subscription ?
The seasons are passing by and our collection gradually grows. We have everything mixed in there. Apparently, if it is a game, our premium users will have more loot, more stuff, more history than standard and free-tier ones. However, as all users are served from the same partition structure, we will see some negative effect of overlap of consumption patterns users of different tiers in one collection.
Let me simplify this. I am a premium user and have accumulated 10000 swords in my inventory. And I want to retrieve them all at once to show my wife where big chuck of my wage has gone.
I will probably consume a significant number of RUs of the partition my data is stored in (remember all partitions have certain RU limits). The same applies to vast number of free-tier users hammering my database because of some marketing event, etc. The trick is that their access pattern will be very different (few items, small requests) but they will overlap with the premium user who may experience some throttling and longer waiting times.
Moreover, over the time if we do not TTL-out stale users, they will be just stored there potentially threatening to blow up the performance of entire solution in case of some large-scale marketing activity. The reason for it is that RUs are distributed by Cosmos DB evenly across all the partitions. As a result, a large amount of stale data will affect number of partitions.
So, better scenario is to provision and profile separate structures (collections, sets of collections) for different tiers based on their unique usage pattern. In addition, one can build a data lifecycle (based on the migration scripts, for example) for moving customers among different tiers – as described in the picture below.
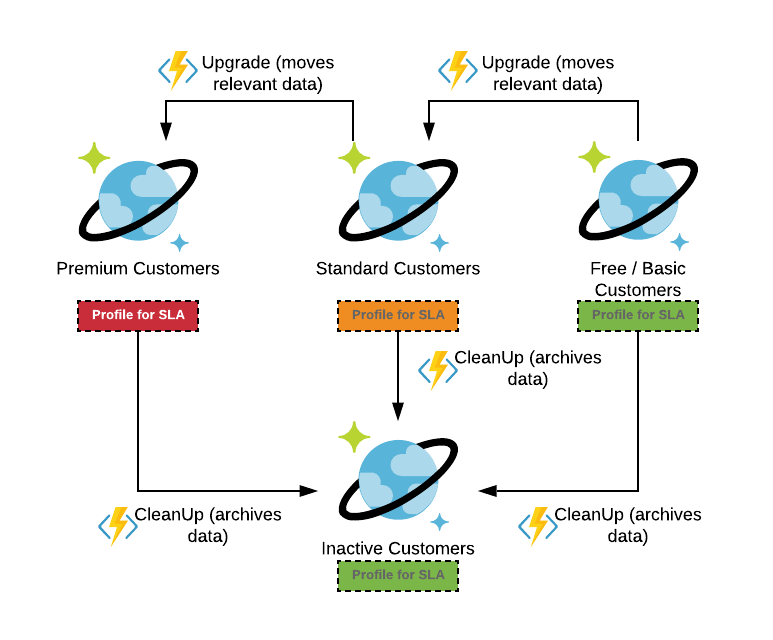
Such solution looks complex but allows you not only to overcome technological complexities of dealing with different usage patterns within the same collection, but also to profile collections for cost and service level. You can guarantee that premium users will have their service and cost of free-tier and inactive users remains under control.
Profiling for Time
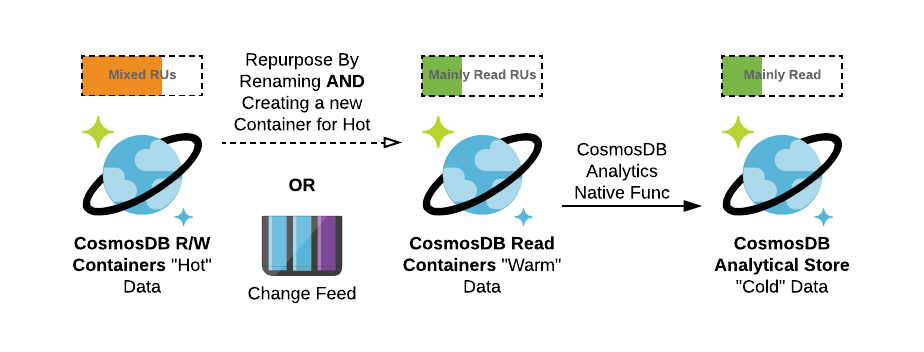
Particular case of Profiling for Purpose is a Profiling for Time. One of the approaches for profiling for time can be, for example, having separate collection for a “real-time” data (aka 5-10 minutes interval), daily and monthly data with Change Feed enabling data lifecycle.
Alternatively, quite often we can see cases where new collections are dynamically added as the period expires (every day, for instance). This approach allows you to keep a constant number of RUs for writes while reducing read-related RUs. With that you can scale for reads only when necessary. Also, you might be interested in offloading infrequently accessed data into Cosmos DB Analytics storage as you can query it later without the need to adapt you application for working with some additional service for cold data.
Caching
In NoSQL PaaS world customers pay per request. And in certain situations, requests are used for repetitive reads. For example, you have a dictionary stored in Cosmos DB collection (such as items in the game).
So, if you just query these items directly from Cosmos DB collection, you will pay on the per-request basis. Thus, extracting information about 10 000 swords in the game we have discussed previously can result (in the worst-case scenario) in 10 000 RU consumption over the time. If the same request is used by thousands of users RUs for this collection will skyrocket.
One of my customers was using 32 request per single user-facing authentication where 30 requests were made against the AppFormsTemplate collection. Times x10 000 users it makes authentication process very costly.
As you may imagine, certainly there is a better way of achieving the same functionality with a way lower cost.
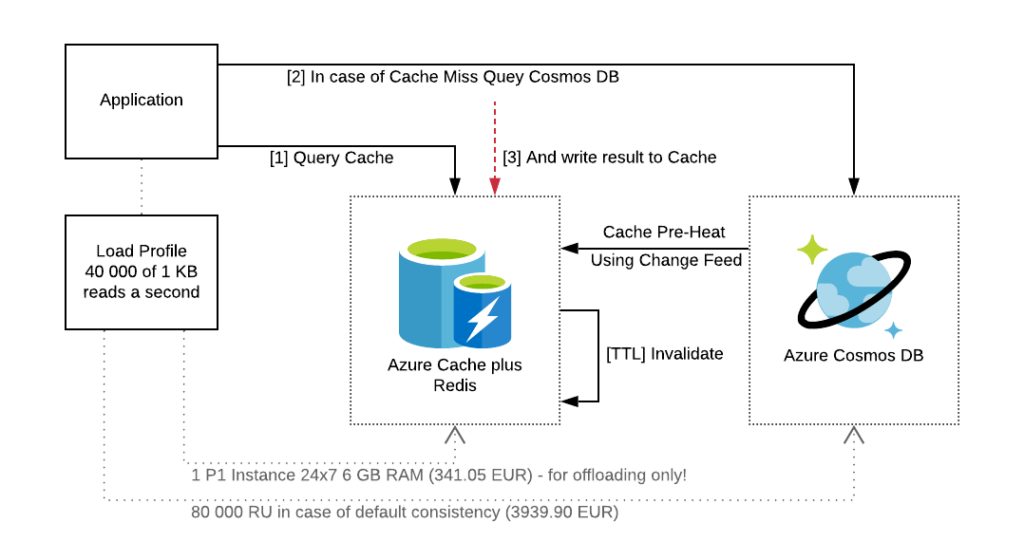
To reduce the number of RUs used to retrieve the same information you can look at various caching tools and strategies. Typically, cache-aside approach is a default option regardless of the tool used for caching itself. The main reason is that Cosmos DB is performant enough to provide fast lookup and the main reason for using caching is to reduce RU cost.
In the certain cases cache pre-population is good idea too (especially when the certain data will be used).
![]() Streaming
Streaming
In certain cases, reads and writes are arriving at a very fast pace and required to be captured immediately. One of the good examples is gaming or device telemetry. Here you may want to check the dynamics of the device and store it for a certain time window as one document.
Let’s assume that we are getting 100 bytes every minute per device and aggregating them in 20-minute intervals. If you ingest data directly into Cosmos DB, your requests pattern will be the following:
- Initial ingestion of 100 bytes documents via single requests – 20 writes x 5 RUs x 3 intervals = 300 RUs per 1 device per 1 hour.
- We need to read our documents, aggregate them, and push them back. For that we can use either Change Feed, or API directly. Applying direct API read approach for this case makes most sense. For reads (in case they are individual reads) we will require 20 reads x 1 RU (for default Session Consistency level) x 3 intervals = 60 RUs per 1 device per 1 hour.
- Having done the aggregation, we need to write back aggregated document to Cosmos DB which consumes 5-10 RUs more.
Alternative can be putting Event Hub in front of the Cosmos DB and doing some aggregations or fast analytics either by using Azure Functions or Azure Stream Analytics before ingesting data into Cosmos DB. That will prevent you from reading data from Cosmos DB, and writing it back eventually allowing you to optimize RUs.
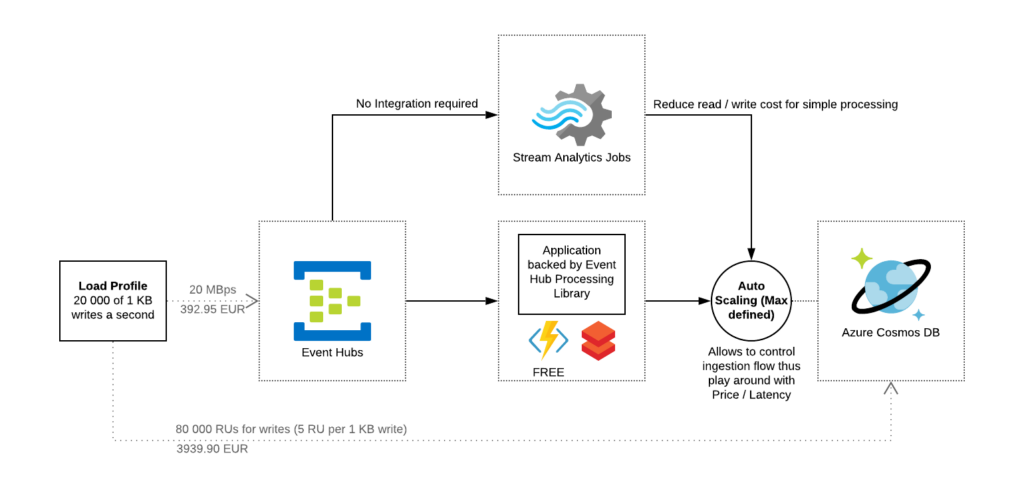
![]() Data Offloading
Data Offloading
It is not a secret that most of the modern NoSQL databases were created to address one of the specific patterns traditional relational databases were struggling with. This pattern is a lookup at scale. For instance, when I need to grab a single document for a one user (shopping cart, for example) and do it as fast as it is physically possible. That was one of the first pragmatical reasons for adapting NoSQL. Currently NoSQL databases are very good in numerous things but typically they are still leaning to the certain workload profiles.
The same with Cosmos DB – it is extremely efficient when it comes to lookups, and can be very efficient for serving pre-aggregated data, doing multi-regional deployments (which is super complex with DIY solutions). But at the same time not that efficient when it comes to wide-open WHERE clauses, doing time-series analysis at scale, etc.
Quite for some time the only means to offload data used to be a custom implementation using Cosmos DB Change Feed. It is very efficient, and I personally found it amazing and very robust piece of technology, however custom implementation is not something everybody will be up for.
To address this Microsoft introduced a new Synapse Link capability which allows you to offload data to Azure Synapse Analytics to benefit from its unprecedented capabilities in large-scale reads. This also allows to avoid multiple large-scale queries in Cosmos DB that can significantly reduce run cost of the service.
One more service perfect for offloading data and working with time-series models is Azure Data Explorer. This service can be either directly integrated with Event Hub (in case you are using it as an ingestion engine) or integrated with Cosmos DB via Change Feed with the use of custom code.
With Data Offloading you will be able to:
- Reduce run rate of your Cosmos DB deployment
- Benefit from fast lookups and queries with narrow WHERE clause
- Enjoy full-scale read capabilities of specialized engines (aggregations, joins, complex queries) like e.g. Azure Synapse Analytics and Azure Data Explorer
All approaches can be found in the following diagram.
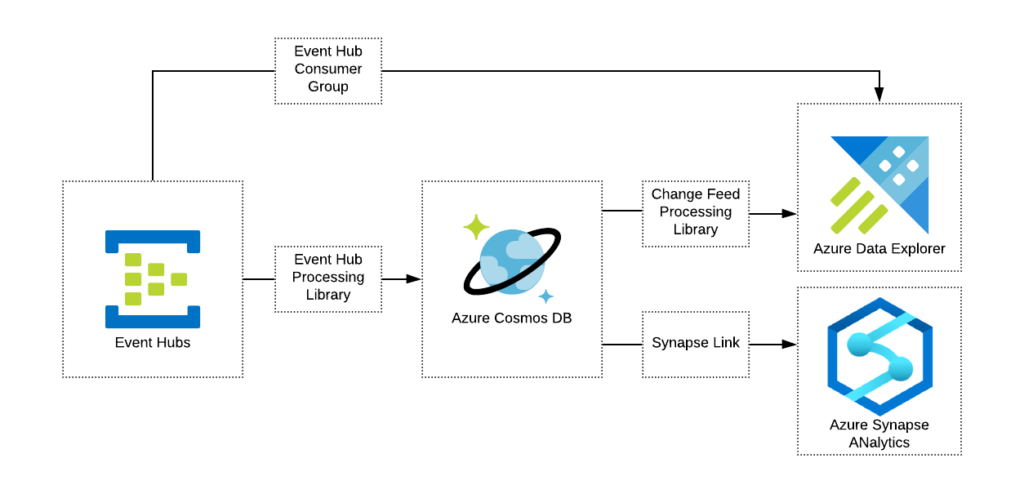
Dealing with Large-Scale Events (LSE) using temporary structures
Imagine that you are a gaming company preparing for a promo campaign on Microsoft Store, Steam, AppStore or other platform, or e-commerce app launching a new aggressive marketing campaign. We all can imagine a Large-Scale Event requiring a lot more capacity than normal.
The naïve approach to deal with such events on the backend side is to scale up related Cosmos DB to significantly higher number of RUs to deal with increased demand. In multiple situations such approach may work perfectly fine but in case scaling requires 10x or higher capacity increase, you may face performance degradation after event ends.
In short, the reason is RUs evenly distributed across partitions and every partition can maintain up to 10 000 RUs. For instance, you have 20 000 RUs and you are fine with 10K per partition performance. Let’s say you need to scale up to 1 000 000 RU bringing you from 2 partitions to 100. When the event is over, you may experience significant issues with performance especially if your partition strategy is not designed to cope with fully randomized / evenly distributed documents. You either keep lots of RUs for maintaining certain performance per partition or migrate to a new collection.
Of course, you have an option to cope with the issues when they arise ?. With such approach the main tool will be your monitoring and data migration scripts (we will discuss them later).
Better approach is to deal with LSE using temporary tables.
The idea of using temporary tables for handling large-scale events is fairly simple. You just provision the collections with the required amount of RUs before the actual event, scale down while waiting and scale up in small increments as soon as you code faces famous error 429 (“Too many requests”).
All the traffic from the event you offload to the temporary collection potentially reusing “dictionary” collections. In fact, if the event lasts only 24 hours you will pay ~24+time for preparation / safeguard to cope with the LSE. As soon as LSE is over, you can use customer scripts or Change Feed (depends on the offloading time and time of event) to move data from LSE collection to the main collection with a neglectable impact on the latter and in a very cost effective manner.
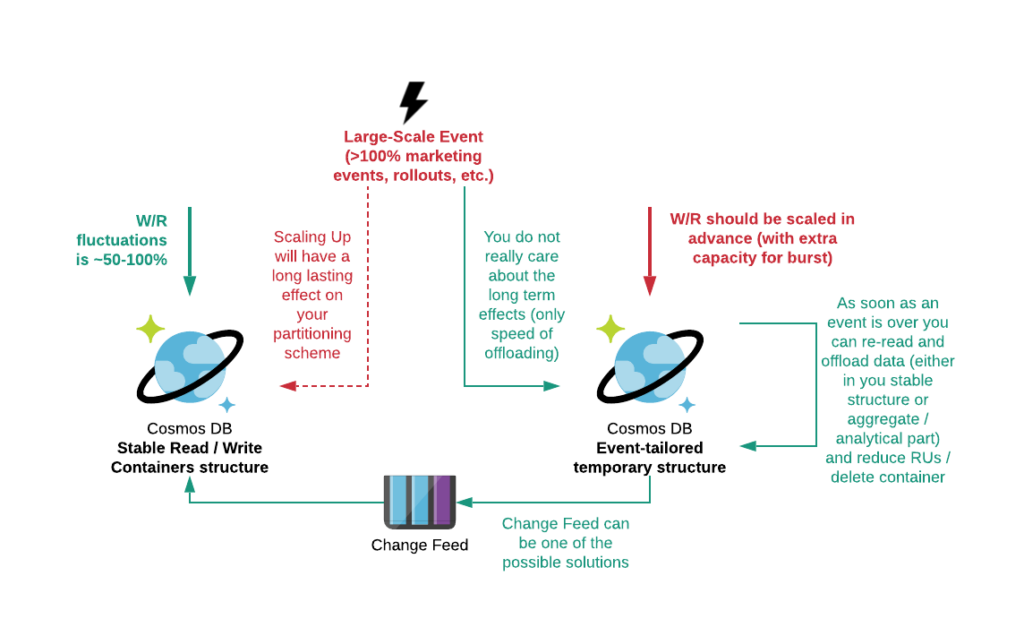
Designing Test / Dev Environment
In several projects I came across with the solutions with hundreds of small collections of data considered predominantly as dictionaries. They were cached but at the same time were very expensive. Why? The main reason was that these collections were provisioned in container-based model meaning every collection had at least 400 RUs assigned (in fact they had around 1000 RUs each). Multiply it by number of dictionaries and the bill becomes enormous.
Interesting part here is that these collections were not actively used (Development environment) and dev team was paying for ~200 writes per second (1000 RU) for each stale collection.
The good thing is that the mitigation is very simple – moving to Database Provisioned model for this case solved the problem.
Please note that in the production environment Database Provisioned collections (containers in Cosmos DB world) behave differently than ones provisioned with their own RUs. Before going to production, it is strongly recommended to test your solution (especially retries and error handling) on the containers with production set up.
Data Migration Scripts as one of the Core Design Blocks
Strictly speaking, Data Migration in NoSQL databases happens quite often. For multiple reasons with a main one to require data rearrangement to achieve best performance results / fix performance issues.
Sometimes we just have loads of different things in one collection, or our shard key is wrong, or we want to change data location – virtually anything. Having such scripts in Cosmos DB is very beneficial as it allows addressing the same issues you can face with any other NoSQL database. For example, you can migrate to another container in case you need to change partition key / merge the partitions at scale / split your collections, etc.
Typically, these scripts should be implemented with the 0-downtime migration. Some of customers with working solutions have implemented them in the following manner:
- The application tries to read from the Target (Sink) Container.
- If read from Sink fails, the application reroutes query to the Source Container. It also marks an item in Source container for migration. Error handling is crucial here.
- Application always writes data into Sink container.
- As soon as the item is marked, it is pushed into Cosmos DB Change Feed. Custom migration scripts (specialized application or Azure Function backed by Cosmos DB Change Feed Processing Library) are grabbing the item from Change Feed and writing it into Sink container. Also, it marks item as migrated in the Source collection Apparently, in the worst-case scenario some conflict resolution may occur here.
- Clean Up scripts are responsible for removing items marked as migrated from the Sink container.
- As soon as migration is finished, the Source collection can be deleted as well as routing information in application error handling.
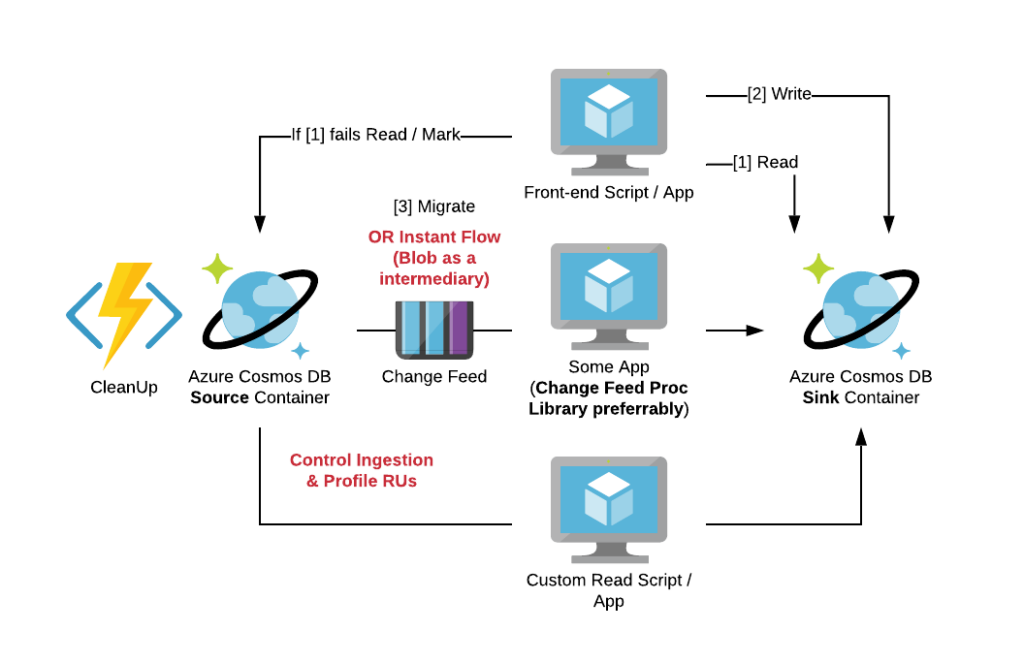
In conclusion
In this article we have discussed several complex approaches for Cosmos DB optimizations. And after all these discussions you may want to ask a valid question: “Why do I need Cosmos DB at all?”
And there are several answers (everything depends on the use case, of course ?):
- First, there is no better tool in Azure ecosystem for lookups at scale. It can be anything – shopping basket, leaderboard, session, device status – literally anything. Add global footprint and you will have a solution providing your customers with the extremely low latency worldwide.
- Second, it is a great tool for storing and distributing semi-structured data. There are some other services that can do it but none of those has so many native integrations with other Azure Services. Azure Functions, Jupiter Notebooks, Change Feed for down streaming, Azure Synapse Link – you name it.
- Third – it is simple – just don’t oversimplify things! Design it right, use it for purpose and it will be efficient and extremely useful tool for solving complex tasks at a very large scale.
- Plus, everything (or almost everything as of now) can be scripted and treated as a code which makes life interesting ?
Remember a rule of thumb – every request has a cost. In every database. The only difference is Cosmos DB puts cost explicitly. Which is fair enough.
Enjoy using it!
P.S. When to Choose What (Cosmos DB edition)
In this section I am planning to introduce some approaches to select proper API of Cosmos DB and some other services. On top you have a write pattern (in blue) and in the bottom you can see read pattern (in green). Based on these patterns you can check the further questions and try to understand the best possible targets. In case read and write path are leading to different services, it means that integration may be required.
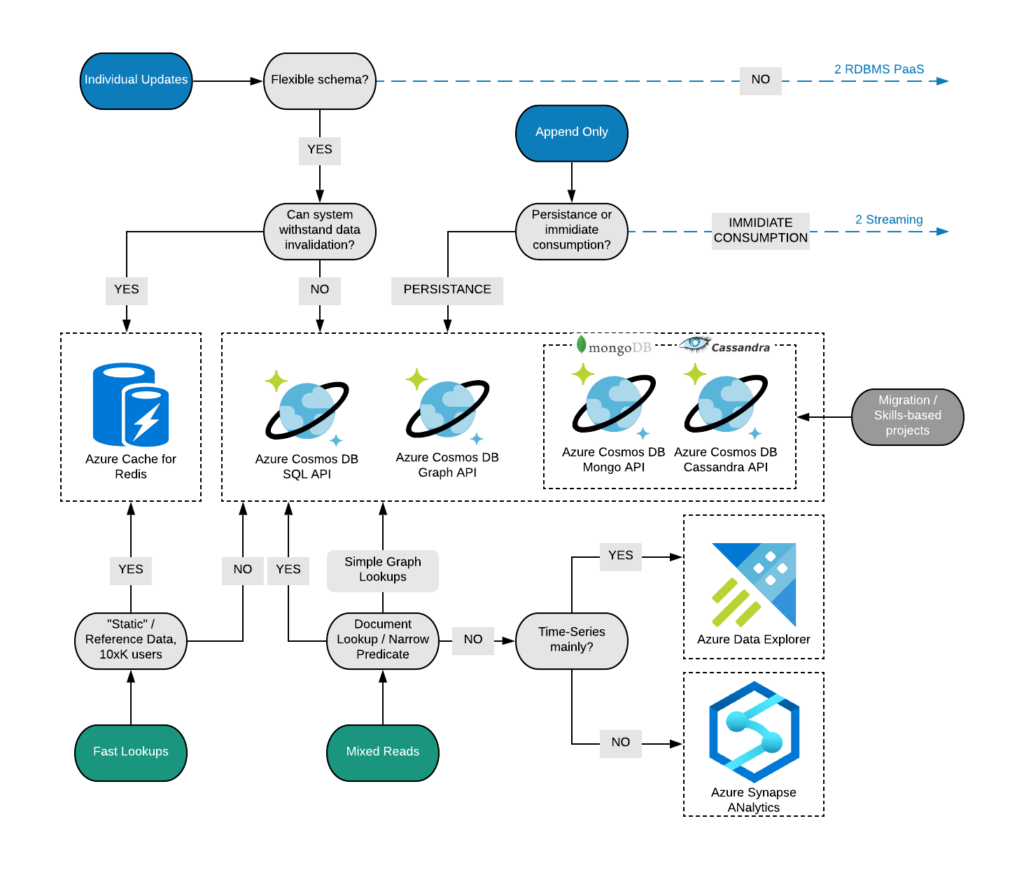
Please do not treat this as a prescriptive guidance rather than an outline of main differences between services and implementations.