This post was written in co-authorship with @Eleni Santorinaiou and @Elizabeth Antoine
Disclaimer. This article represents personal experience and understanding of the authors. Please use this for the reference only. This article doesn’t represent official position of Microsoft.
Simplicity is an ultimate sophistication.
— Leonardo Da Vinci
Before We Begin
In this article we are talking a lot about different methods of comparison and selection of databases. Also, we are presenting an alternative approach for looking and considering different options. At the same time, I would like to highlight that this is just one of the viewpoints. Please use below as a reference rather than a prescriptive guidance.
And may the force be with you.
SHOKING HAZARD! Equipment you might need before reading this article.

Important note: What is and What isn’t this Document
This Decision Tree is:
- Map of the Azure Data Services with the main goal to help you to navigate among them and understand their strengths and weaknesses.
- Supplementary material to the officially published Microsoft documentation helping you to define and shape your thought process around selection of the certain data technologies and using them together in your solutions.
This Decision Tree is not:
- A Definitive Guide to selection of Data Technologies.
- Business / politics related document. All the criteria we were using are purely technical.
- Not a pattern or use-case focused document.
- Not a competitive analysis of any kind.
We are keeping some responsibility on maintaining this document as long as we can but still would recommend verifying points in the document against Microsoft official guidance and documentation.
Also do not hesitate to apply common sense and, please check things before putting into production. Not all the situations are the same / similar.
The article has four chapters:
Chapter 1: Read and Write Profiles – explains the premise of the decision tree.
Chapter 2: Navigating Through the Decision Tree – guide to navigate through the decision tree.
Chapter 3: Mapping Use Case to the Decision Tree – examples of how the decision tree is used for different use cases.
Chapter 4: Getting Access and Providing Feedback – Finally, do not hesitate to provide us with your experience / feedback. We will cover how to do this in this chapter.
Chapter 1: Read and Write Profiles[1]
Our data technologies were developed mainly for two major purposes. And guess what, these are not encryption and obfuscation rather reading and writing data. Actually, mainly for reading as (and I hope you agree with me) there is no point in writing data you cannot read later on.
Surprisingly, we never compare data technologies based on their actual read and write behavior. Typically, while compare data technologies we are (pick all that applies):
- Focusing on some subset of the requirements.
- Checking “similar” cases.
- Adding technologies to the design one-by-one.
- Using “Reference Architectures” and “Patterns” in seeking for forsaken tribe knowledge.
- Surfing Internet long nights in a hope that by modifying the query we can find some kind of sense.
Basically, we craft design of our data estate based on experience, preferences, and beliefs. When our group faced first time the need to compare different technologies and recommend one, our first thought was – it is impossible. How would you compare NoSQL database to Ledger database?
Very simple – using their fundamental read and write goal as a foundation for such a comparison. The essence of the technology remains the same as well as a goal of its creation. A sheep cannot become a tiger ?
Well, in most of the cases ?

Picture: Paul Faith / PA (https://www.telegraph.co.uk/)
This beautiful “Tiger Sheep” won the first prize in the first ever sheep fashion show at Glenarm Castle in Northern Ireland, as part of the Dalriada Festival.
To give you an example, Apache Kafka was created to write tons of small items in sequential fashion and read them one-by-one (at-least-once delivery is a direct consequence of it). Does anyone use it for large-scale analytics on archival data? NO! The reason is simple – because of its read-and-write profile. These are widely known and defined by the industry (effectively, by all of us) and are used quite for some time.
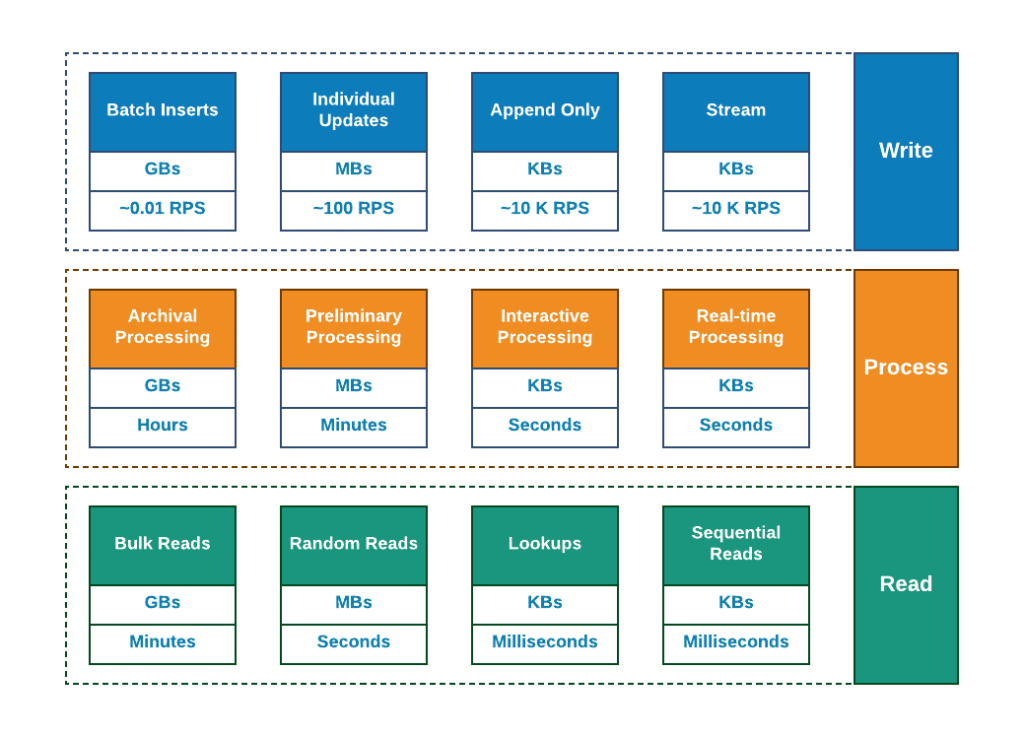
Let us take a look at the following diagram (I am borrowing this from one of the previous articles “Why so many databases?”).
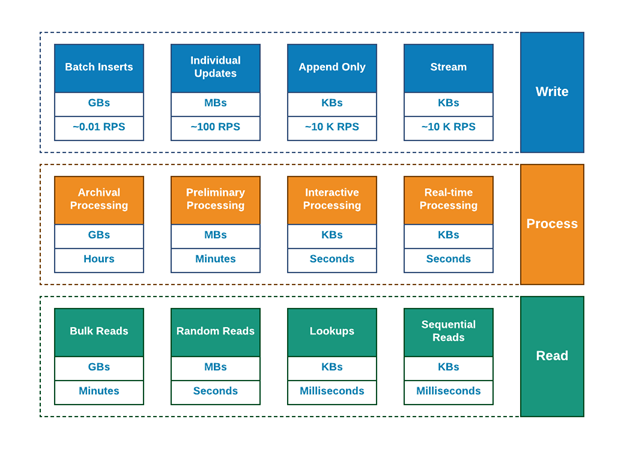
Intuitively (and, hopefully, obviously), if some data has a write path it should also have a read path and may or may not have one or more processing capabilities / tools / approaches.
Of course, loads of the technologies and vendors are claiming that one single solution can solve all the possible issues but the entire history of rise of Data Technologies over the last decade shows that it is surely not the case any longer.
Side Note: In fact, when some great technology emerges it always refers to the concept of “Purpose Built Technologies” while becoming more and more mature, it starts claiming to fit in virtually any use case possible.
Well it seems that we have finished with WHY and already started with WHAT? Let’s move on and show you one of these Decision Trees in more details.
Chapter 2: Navigating Through the Decision Tree
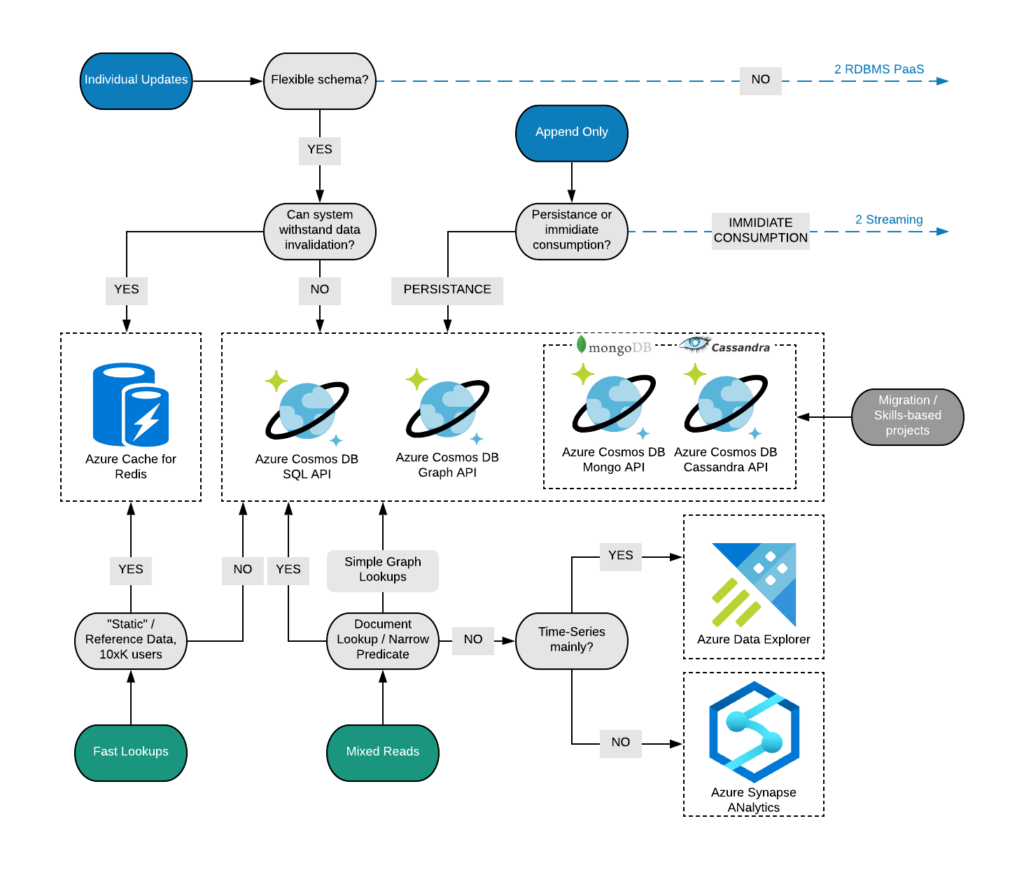
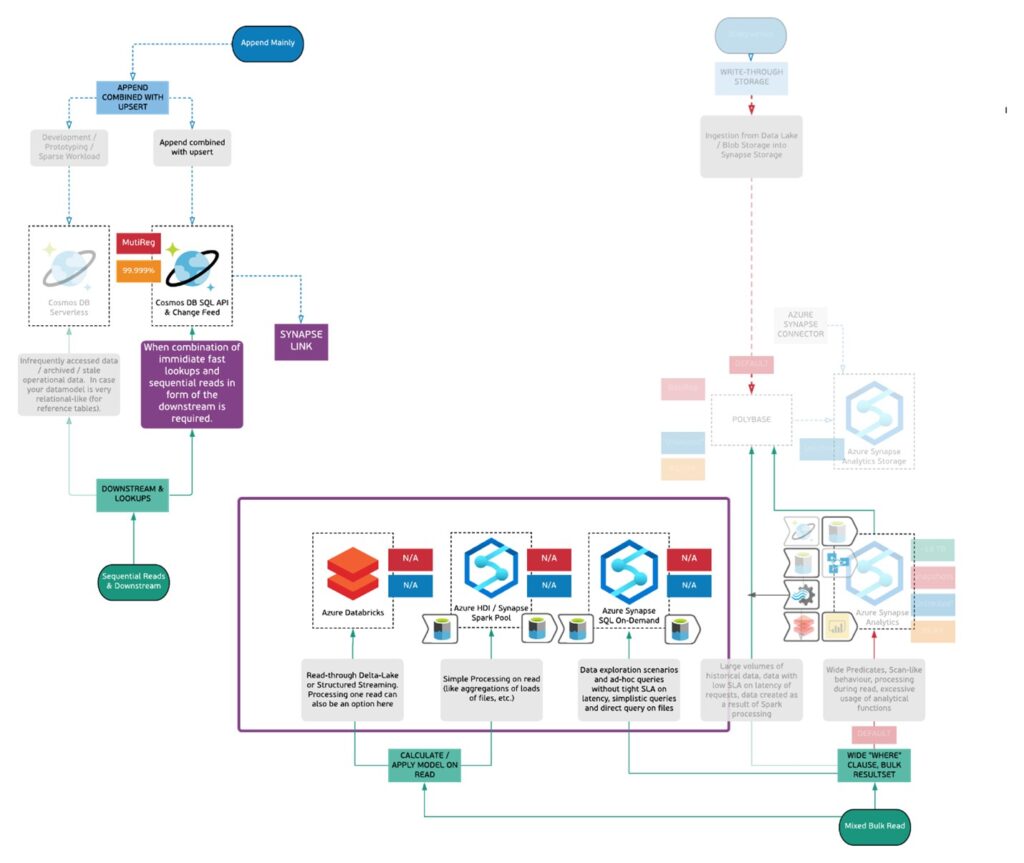
So, in order to help you to navigate across ever-changing and pretty complex Azure Data Landscape, we have built a set of decision trees based on the concept of read and write profiles. Conceptually Decision Tree looks very simple.
Well, it is not that simple obviously. The good thing is that it covers almost entire Azure Data Portfolio in one diagram (which is comprised of more than 20 services, tens of SKUs, integrations and important features). So, it just cannot be super simple. But we are trying ?
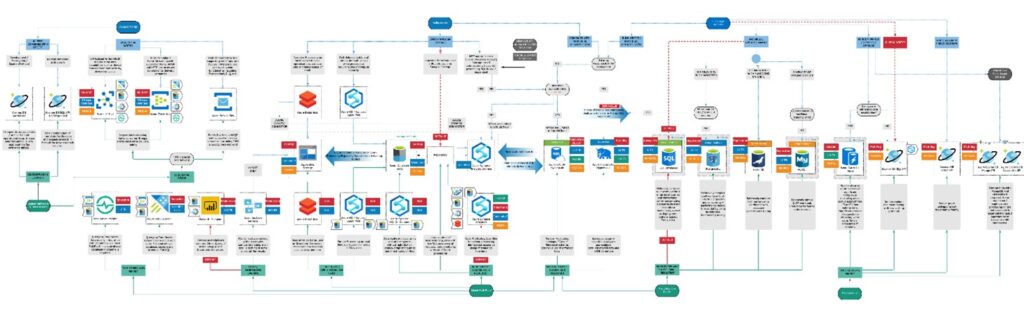
In order to guide you through it, let’s just paste a small example (subset) of this decision tree here and demonstrate you some of the main features and ways to navigate through them.
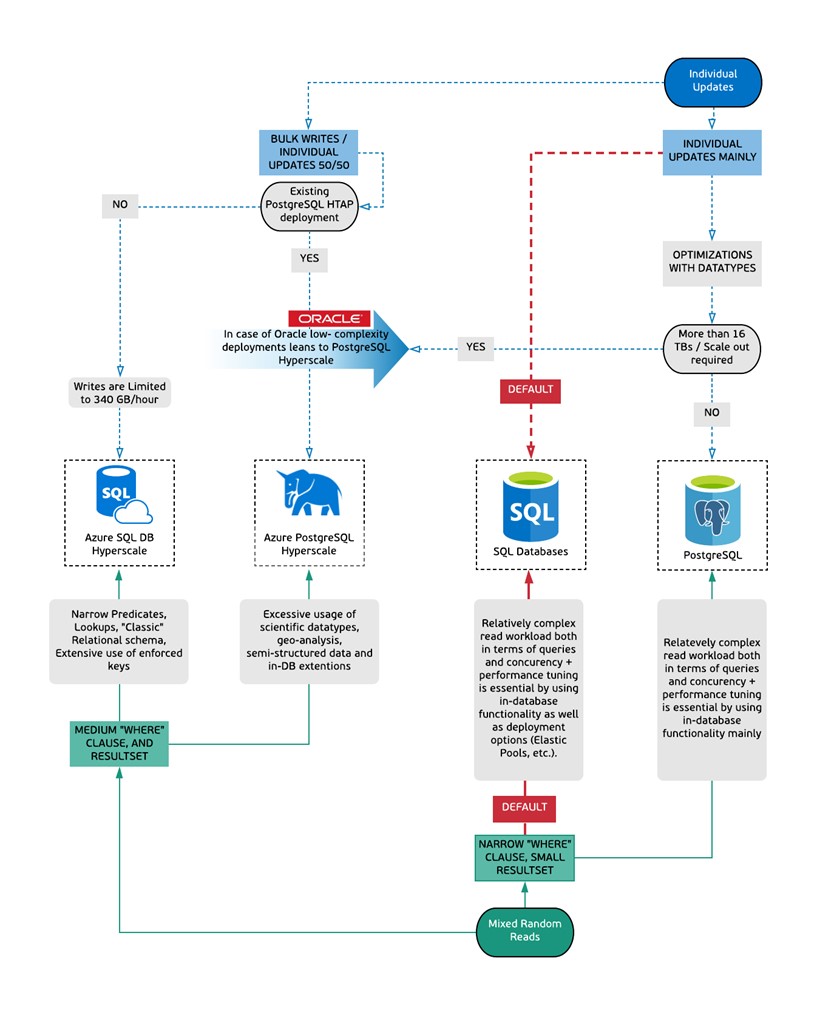
Basic Navigation
It is comprised of two main paths read and write patterns. Write pattern from top to the middle marked with blue boxes and lines and read pattern – from the bottom to the middle marked with greenish lines and boxes. This represents some of the fundamental differences in behavior of various technologies.
In the grey boxes you can see either questions or workload descriptions. As mentioned, this approach is not strictly defined in the mathematical sense rather follows industry practices and includes specific features and tech aspects which differentiate this technology from others.
In case of the doubt, just simply follow yes / no path. When you have to choose among descriptions, you have to find the one which fits best.
Below are the components of a simple navigation.
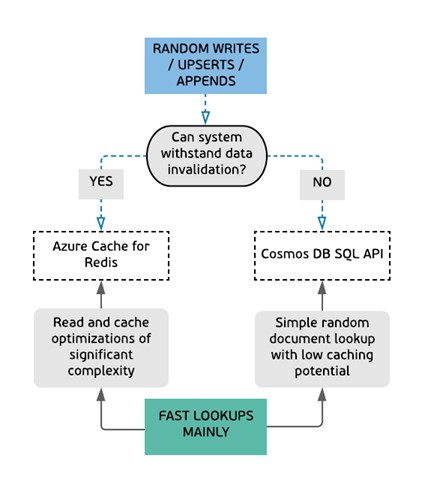
Leaning
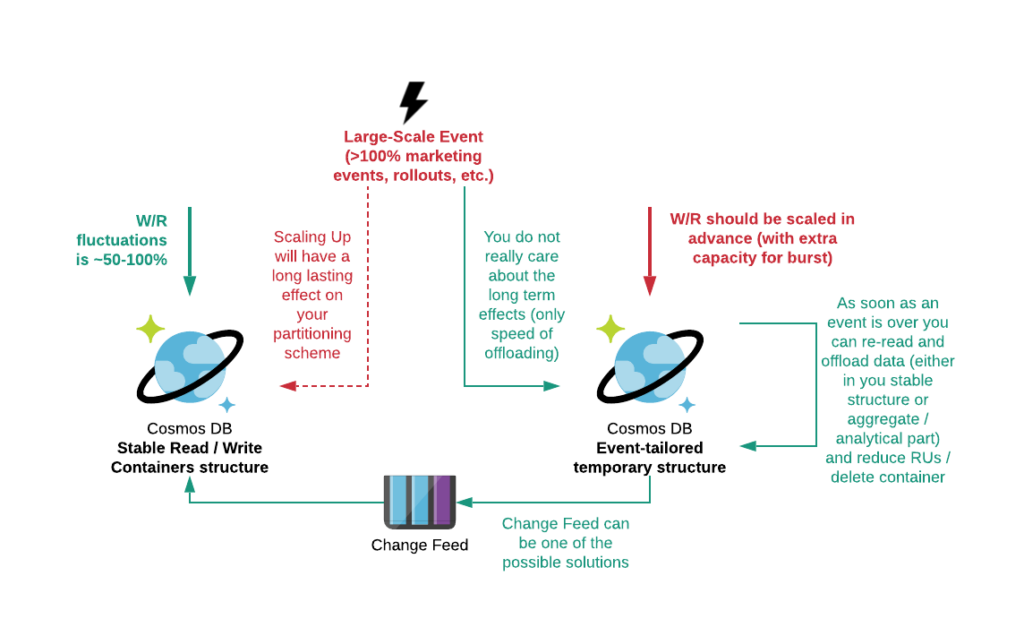
There are also some more tricky parts, where you cannot say with certainty which workload will be a better fit. In such cases we are using wide blue arrows representing “leaning” concept. Pretty much like in one of the examples below.
There is one more style of “leaning” which is represented by the so-called “paradigm”. In some cases there are technologies which will be preferred when you are using particular programming language or stack. In our decision tree this is represented by the notion of “paradigm” as described on a picture below.
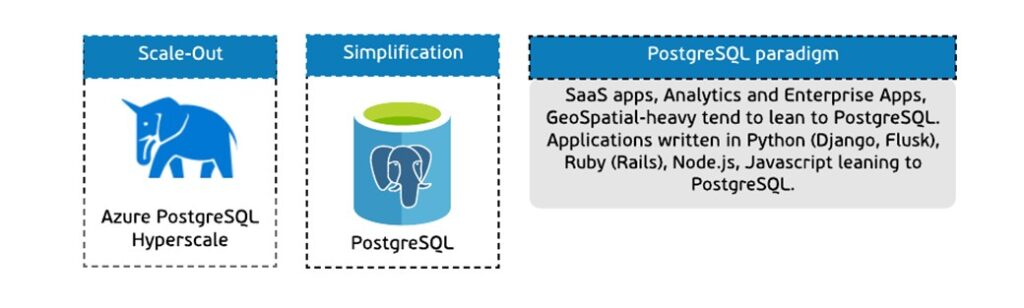
Typically, in one paradigm we have more than one product available. To distinguish the main goal of the product within certain paradigm we are using some code wording like in the example above. This goal is represented by one word which is shown above the box with the service and holds the same color as a paradigm.
Default Path
In most of the technology patterns we also have a “default” path for reads and writes. Typically for a greenfield project this is the easiest and richest path (in terms of functionality, new features and, possibly, overall happiness of the users).
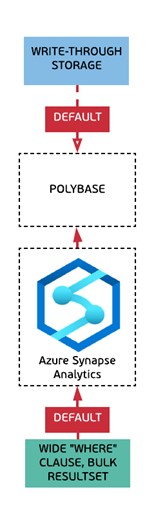
Drill Down
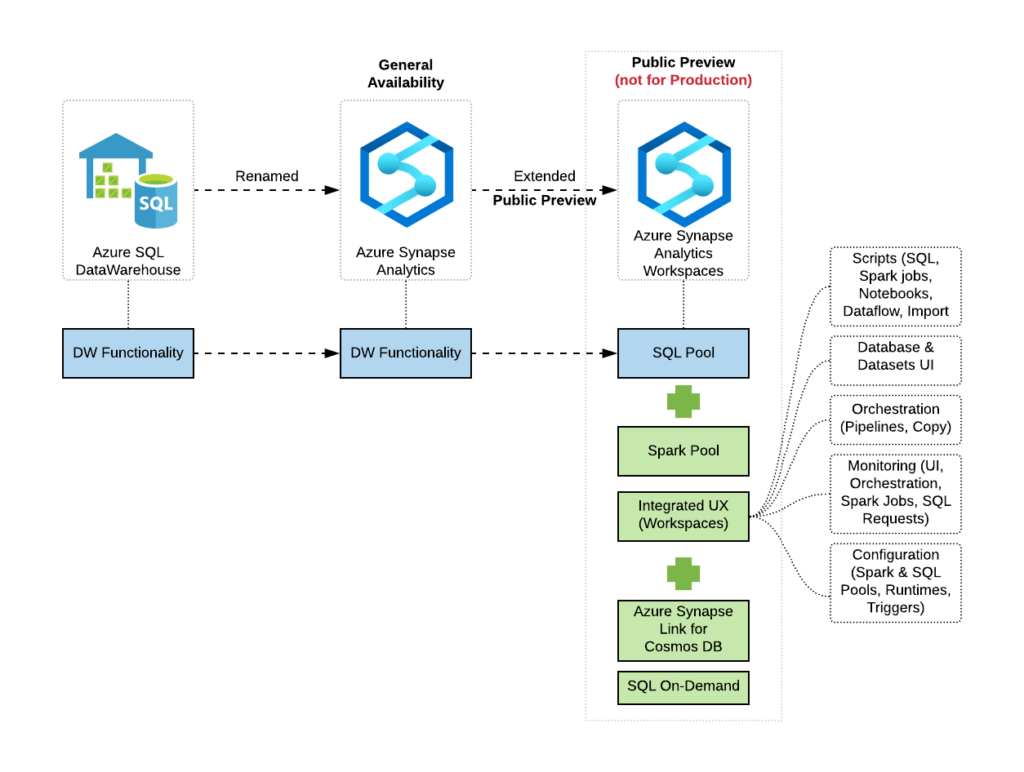
In some cases, we also have implemented a drill-down approach to simplify the navigation. Drill downs lead to a different diagram explaining some details around service offerings or SKUs for a particular product / service.

Drill down will bring you to the new Decision Tree which is specific for the particular technology (such as SQL Database on Azure, PostgreSQL or others). These Decision Trees are following same / similar patterns with some reduced number of possible read and write profiles (as shown on a diagram below). On these Decision Trees SLAs, High-Availability options as well as Storage and RAM limits are defined on the per SKU basis.
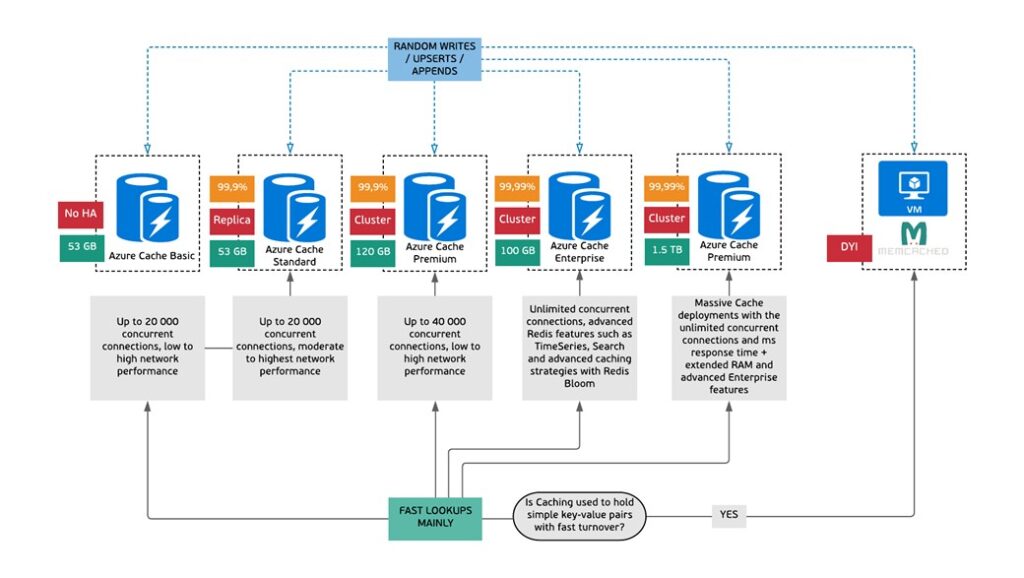
SLAs & Limitations
Another cool feature of the Decision Tree is a depiction of maximum achievable SLA, High Availability options and Storage / RAM limits (when it makes sense).
These are implemented as shown below. Please remember that these might be different from SKU to SKU and only the maximum achievable is shown on the main Decision Tree.

Please note that all / most (just in case we forgot something) of the icons with limitations, HA & SLA are clickable so you will be redirected to the official Microsoft documentation.
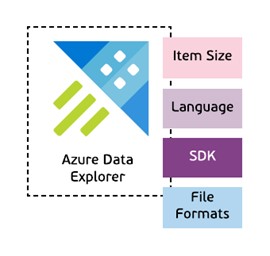
Developer View
One of the newest features is a Developer View. In this view we are listing all the Procedural Languages supported by the technology as well as SDKs and some important limitations of size of items or resultsets where applicable. Also we are depicting supported file types and formats.
We are planning to make these references to the official Microsoft documentation (pretty much like it was done with SLAs, Storage, etc.)
Read and Write Profiles Do Not Match
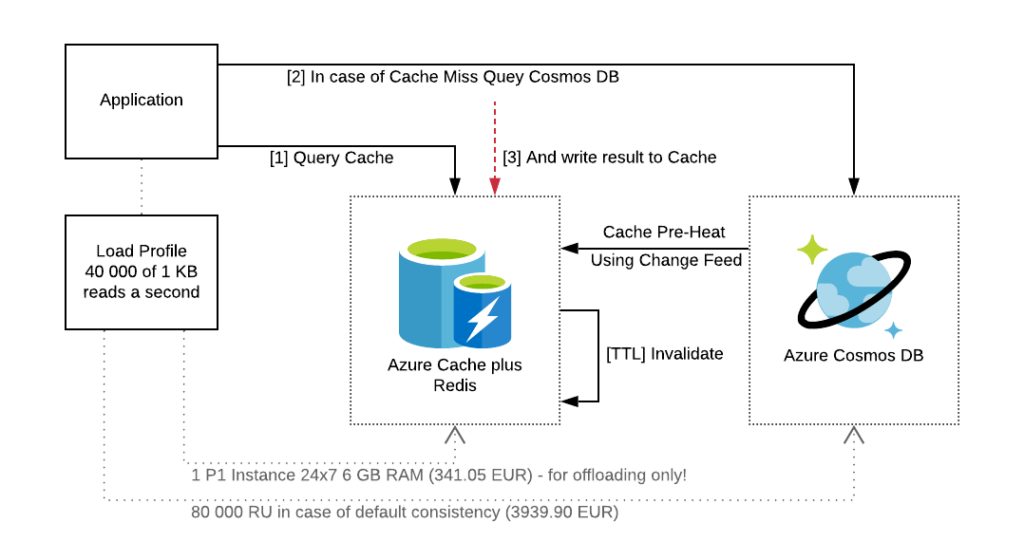
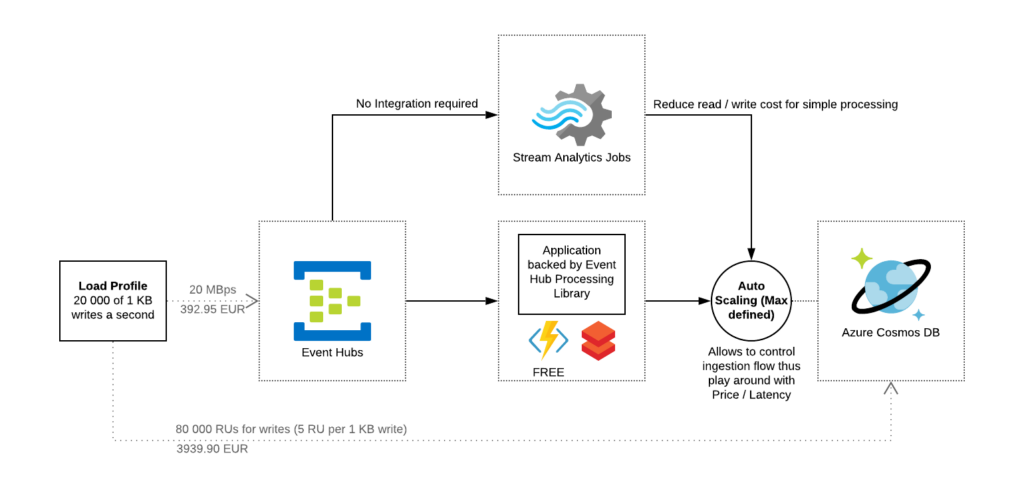
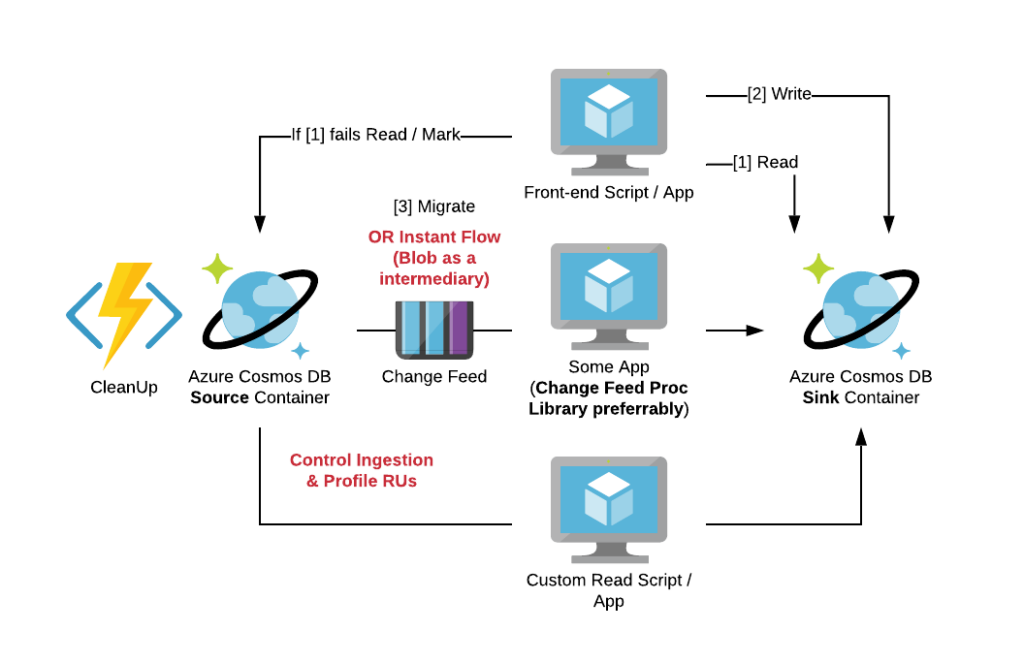
With two separate profiles for reads and writes there is a very important and frequently asked question: “What if read and write profiles do not match?”
Let’s answer with the question. What do you typically do when your technology used for writes is not suitable for doing reads with the pattern / functionality required? The answer is quite obvious – you will introduce one more technology to your solution.
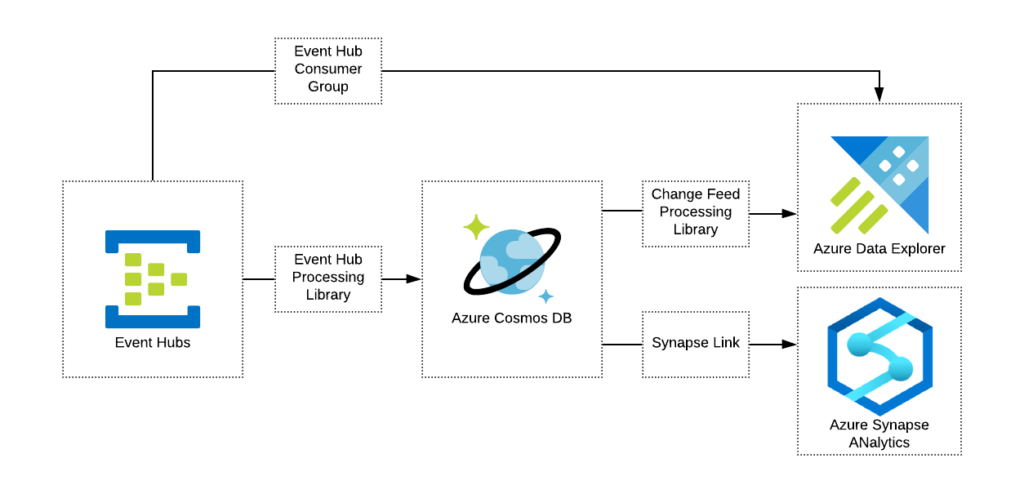
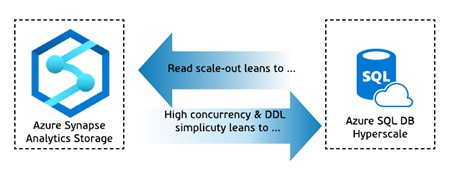
To help you to find which components can be directly integrated with each other we have introduced the concepts of “Integration In” and “Integration Out”. The example of the notation is shown below.
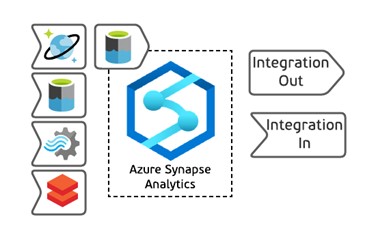
In this example we can see that Azure Synapse Analytics can accept data from:
- Azure Cosmos DB using Azure Synapse Link
- Azure Data Lake Store Gen2 / Blob Storage using CTAS functionality of Polybase
- Azure Stream Analytics via output directly
- Azure Databricks using Azure Databricks Connector for Azure Synapse
And export data through ADLS Gen2 using CETAS statements of Polybase.
As you may see on the Decision Tree itself, we can only see that such an integration is possible, but we are not specifying exact mechanism or its limitations. If you click on this icon, you will be redirected to the official Microsoft documentation.
One more important note here. We do not show Azure Data Factory on this diagram as this is the service which meant to be used across the entire Azure portfolio and adding it to the diagram will make it even more messy. So, we implicitly mean that Azure Data Factory can be used to integrate with most of the services mentioned on the Decision Tree.
Ok, let’s take a look on how to apply this in practice. In the next chapter we will cover some examples of using Decision Tree to craft the architecture and select appropriate technology for your workload.
Chapter 3: Mapping Use Case to the Decision Tree
Why and How to Map Your Use Case to the Decision Tree
As you can see, these Decision Trees can be pretty complex but at the same time they represent almost full subset of data technologies. At the same time, industrial and technological use cases might still be very relevant especially if combined with the Decision Tree as a frame for discussion.
In such case one can clearly see not only choices made but also choices omitted. Also, it can immediately give you an idea which alternatives and when you may consider.
HOW? Just shade out all what is not needed and add your relevant metrics for the decisions made (for instance, predicted throughput, data size, latency, etc.)
Let’s take a closer look on how we can do it. And we will start with a small example.
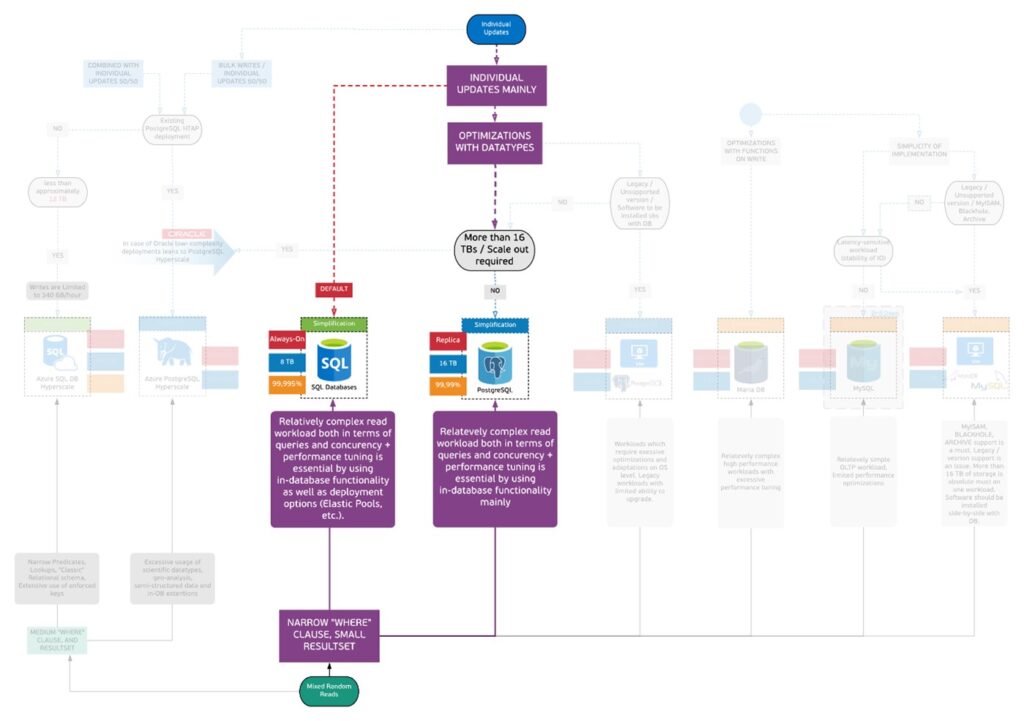
Use Case: Relational OLTP / HTAP
In this example, your business specializes in the retail industry and you’re building a retail management system to track the inventory of the products in each store. You also want to add some basic reporting capabilities based on the geospatial data from the stores. To decide what is the best database for these requirements let’s take our uber tree and start from a write pattern.
- The data for the orders, users and products get stored as soon as it arrives, and it gets updated in an individual basis. The throughput of such system is not high.
- The schema of the entities is expected to be the same and a normalized logic is preferred to make the updates simpler.
- Your store needs to support geospatial data and indexing
This already narrows down our choices in the RDBMS space. Moving to read profile.
- The queries will have different levels of complexity, a user might need to get the stock of a specific item in a single store, or even join the data from stores that are located to a distance close to a specific store.
- The store manager will need to have a report available that it will show which days and time most traffic is expected.
- HQ will need to identify the positive or negative factors that have effect on a zip code’s total sales to increase the sales coming from the retail channel.
Since the queries have some geo-related clauses Postgres could be a good candidate and since some analysis and visualization is required SQL would be another option. Going further down, you could discuss with the development team the application stack and more specifically the programming language. If the app is written in node.js or Ruby, Postgres will be a great choice, otherwise, with .net Azure SQL will be the perfect solution. Other factors to take into consideration would be the amount of data to be stored, how to scale out if the data increases and the HA SLAs.
Use Case: Mixing the write and read patterns
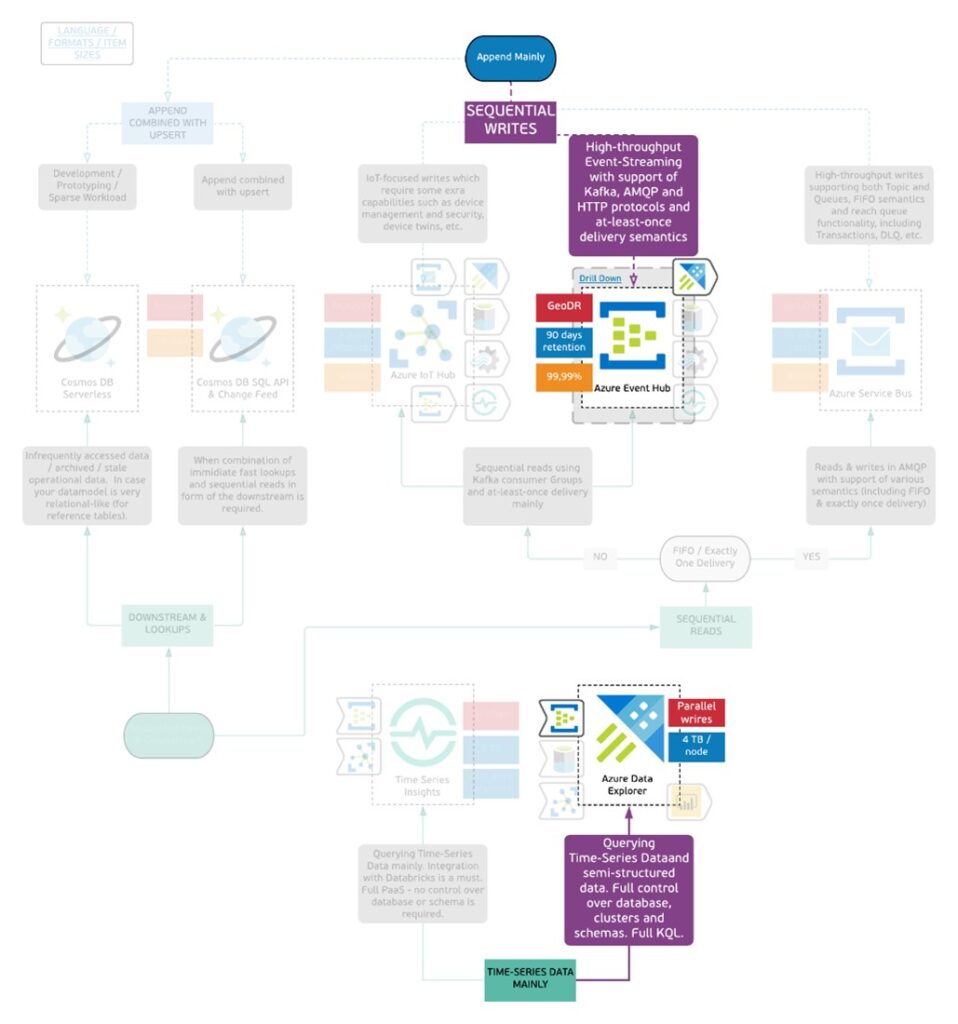
The next example of how the Uber Tree can be used as a tool to produce a data architecture comes from the gaming space. Your team is building new features for a massively multiplayer online game and they need to collect and store all actions of the players, analyze those that matter in near-real time and archive the history. As usual, we will start from the write profile.
- The events are captured and stored and are never updated.
- High throughput is expected with hundreds of thousands of events per second.
For the specific use case seems that there is a single path for the writes; Event Hub answers those requirements. But the way we will process and read the data is not in a sequential order. More specifically:
- The data needs to be read in a time-series manner prioritizing the most recent and aggregating based on time.
- Need to narrow down the analysis to the metrics that are relevant for a particular game and also enrich the data with data coming from different sources, so basically, you need control over the schema.
On the read pattern, it looks like Azure Data Explorer would be the most suitable store.
In this case, where two different profiles for the write and read are identified, we will leverage two solutions that are integrated. Azure Data Explorer natively supports ingestion from Event Hub. So, we can provide a queue interface to the event producer and an analytical interface to the team that will run the analysis on those events.
Use Case: Analytics
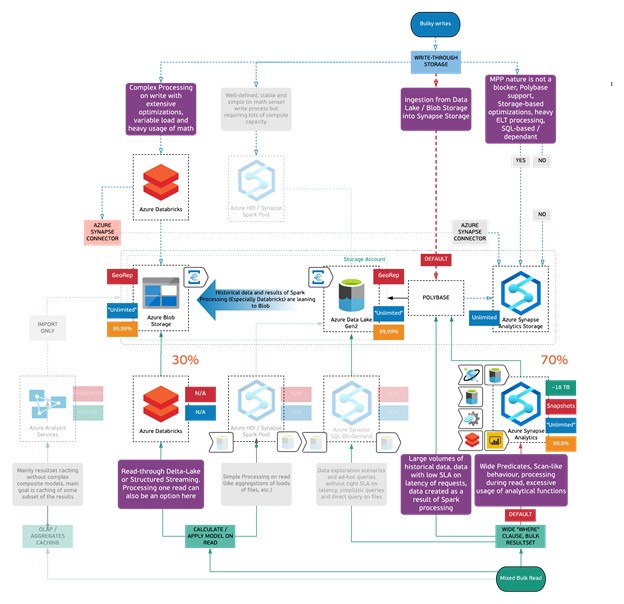
In this example, your business specializes in the energy industry and you’re building a analytics platform for power plant operation and asset management. It would include all the necessary pieces, from condition monitoring and performance management to maintenance planning, risk management and market scheduling. To decide what is the best approach for these requirements let’s start with the write patterns of our uber tree.
- Since operating a power plant generates a large amount of varying data, the platform must have the ability to process batch data coming in huge volumes.
- 70% of the data is structured.
- The data coming from meters need to be processed near real time and involves complex processing before it can be unified with the data from performance, risk, and finance systems.
This already narrows down our choices to Azure Synapse and Azure Databricks with combination of Azure Storage & ADLS Gen2 with Polybase
Moving to read profile.
- The queries will have different levels of complexity,
- Takes the data and information from the source systems, merges them to create the unified view to make it possible to monitor the performance of the plants/assets through an executive dashboard.
- Machine learning to provide decision support.
Since the requirement is to unify the huge volumes of data across different source systems where 70% of the data is structured, PolyBase would be right choice to land the data in Azure Synapse Storage and perform the transformations using Synapse SQL to create the dimensional model for historical analysis and dashboarding. There is also 30% of the unstructured data that needs to be processed before merging that into the dimensional model where optimized spark engine like Databricks is a perfect fit for purpose and also can be extended to the ML use-cases for decision support. Other factors to take into consideration would be the amount of data to be stored, how to scale out if the data increases and the HA SLAs.
Use Case: HTAP
In this example, your business specializes in the healthcare industry and you’re building a platform for patient outreach and engagement. You are trying to build an advanced analytics solution looking to take chronically unwell patients that have high utilization of emergency department/ unplanned inpatient services and, through a more coordinated provision of ambulatory services keep them well at home. To decide what is the best approach for these requirements let’s start with the write patterns of our uber tree.
- The write pattern itself is largely event-driven and completely serverless, which aggregates messages from close to 200 data sources across the organization.
- They also have a million different EHRs and other sources of data (Radiology, Cardiology, Surgery, Labs Systems, etc.) and also millions of transactions per day.
- Have laws requiring data for each patient to be kept for at least 7 years (28 years for newborns).
This already narrows down our choices to Azure Cosmos DB for capturing the patient data across the different systems and to decide on the ability to build the analytics solution on the data captured in cosmos DB, we now look at the read profile.
- Real time data must be available as soon as the data is Input, updated or calculated within the Cosmos DB database.
- Complex analytical queries must report results within 900 seconds.
Since the requirement is to provide the ability to do advanced analytics on the data captured in Cosmos DB but in near real time, the ETL approach cannot be leveraged here. The Synapse Link in Azure Synapse Analytics or Databricks could be considered as the possible options. If the usage pattern is ad-hoc or intermittent, you may gain considerable savings by actually using a Synapse Link solution compared to a cluster-based solution. This is because the SQL On-Demand will be charged per data processed and not per time that the cluster is up and running, hence you wouldn’t be paying for times when the cluster is idle or over-provisioned.
Chapter 4: Getting Access and Providing Feedback
Here we are. Thank you for being with us up to this moment. This will be the shortest Chapter – we promise ?
You can find interactive Decision Tree on GitHub Pages by following this link: http://albero.cloud/
All the materials can be found in a public GitHub Repository here: https://github.com/albero-azure/albero
You can provide your feedback / submit questions and propose materials via Issues of the GitHub Repository.
Thank you and have a very pleasant day!
BTW. Just tested it from my smartphone and it also looks pretty nice ?
[1] In one of scientific works (still in review and will be published soon) Andrei Zaichikov is proposing a formal definition of read and write profiles in form of quantifiable random numeric vectors and scales. It is not used in this work.