Hi there
I was always wondering – why we have so many different databases. If you take a look at raking published on https://db-engines.com/, you will easily find out that there are 334 database technologies.

The question is if we need that many and why people are using that many databases. I know that it is a complex question and there are various different viewpoints on it – historical, cultural, technological, etc.
Let me describe how I see it from purely technical viewpoint.
We have numerous different types of the database-related workloads. Typically, what we do in the database is read, write and process (in most cases). These processes are different by nature and we do care about different parameters of each process. Also, as you may imagine, database exists in some environment and not always we can or want to influence or change it. So, we have a combination of database and environment it exists in.
If we classify three major processes we have in the database and will add some main parameters we do care about to the single chart, we will have some initial idea from where this variability comes from.
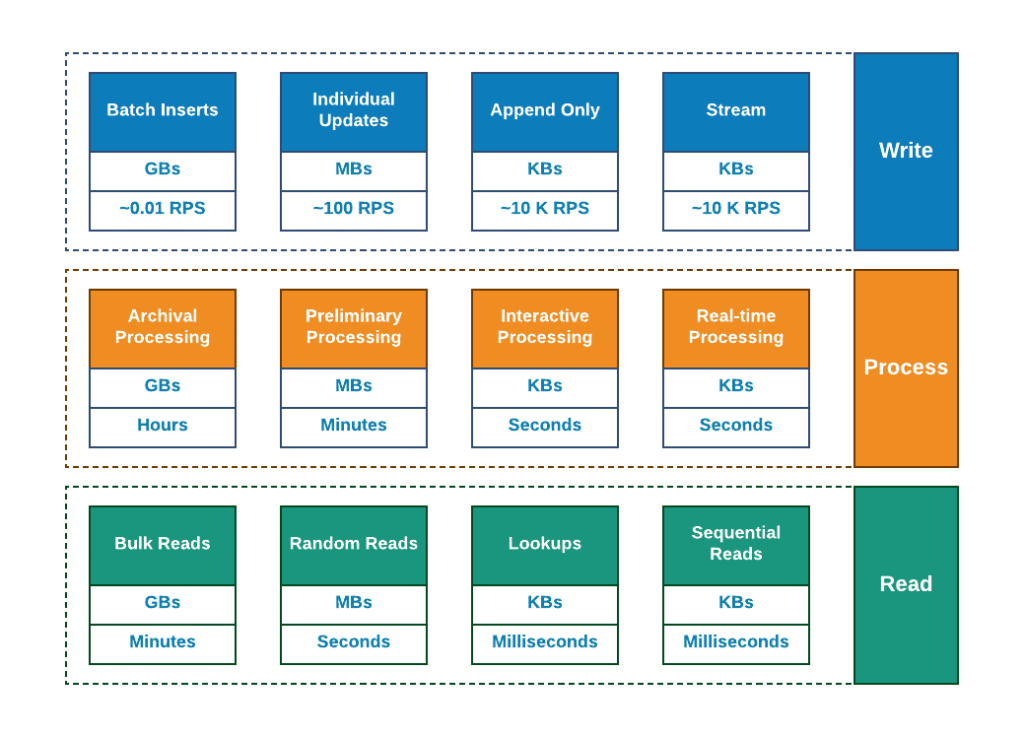
Indeed, this is a simple and self-evident, right? We do have many types of the technologies (like MPP, HTAP, OLTP, Cache, Stream, etc.) to accommodate different read and write patterns.
This diagram also can illustrate the reason behind the rise of polyglot persistence. If you have streaming as a write path and then consuming data in large batches there will be, most probably several major technologies and these will be decoupled one from another. At the same time if you are processing time, required read latency and write throughput are within the same pattern probably you will end up using one single database technology for most of your needs.
That‘s interesting but the one thing that this approach doesn’t explain is why we have hundreds on them (even if we put development fashion and personal preferences aside). In order to explain this we will need one more graph.
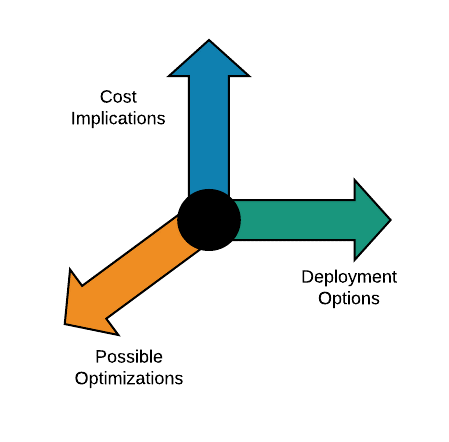
Apart from the workload,
environment and their parameters we are also looking on the several main things
(even if we are not doing it from the start we will be considering them soon
after the real works begins), such as:
- Deployment Options – for example, hybrid deployments, mobile deployments, deployments on specific hardware as well as possible deployment optimizations. This also includes HA & DR, maintenance routines, etc.
- Possible Optimizations – most of the existing databases were born when developers faced new or unique challenge, so those technologies were adapted for solving very narrow cases. For instance, CouchDB is very good in supporting replications of various styles, SQL Lite works on cell phones and Aerospike is extremely efficient when it comes to in-memory processing. Even in Caching (which is very narrow) people are using Memcached for working with small Key-Value pairs (very efficient when it comes to RAM) while using Redis for more complex scenarios.
- Cost implications – licensing, hardware, ability to scale and optimize cost based on various techniques.
Combining these two graphs together will give us a pretty good (but for sure even not close to full) picture on why we still have so many database technologies.
Choose wisely 😉
